¿Qué es data cleansing?
Data cleaning es el proceso de revisar, limpiar y transformar datos para que sean más precisos y útiles para un análisis. El objetivo de la limpieza de datos es eliminar o corregir datos erróneos, incompletos, duplicados y inconsistentes para mejorar la calidad de los datos. Esto incluye la identificación y eliminación de datos no deseados, la detección y corrección de datos erróneos, el formateo de datos y la conversión de datos a un formato adecuado para su uso.
El data cleaning es fundamental porque garantiza que los datos que se van a utilizar para analizar sean precisos y fidedignos. Esto significa que los datos estarán libres de errores, duplicados, incompletos, redundancias y otros problemas que pueden afectar la precisión de los resultados. El data cleaning también ayuda a minimizar la cantidad de tiempo y recursos necesarios para realizar análisis de datos, así como a aumentar la velocidad de la información.
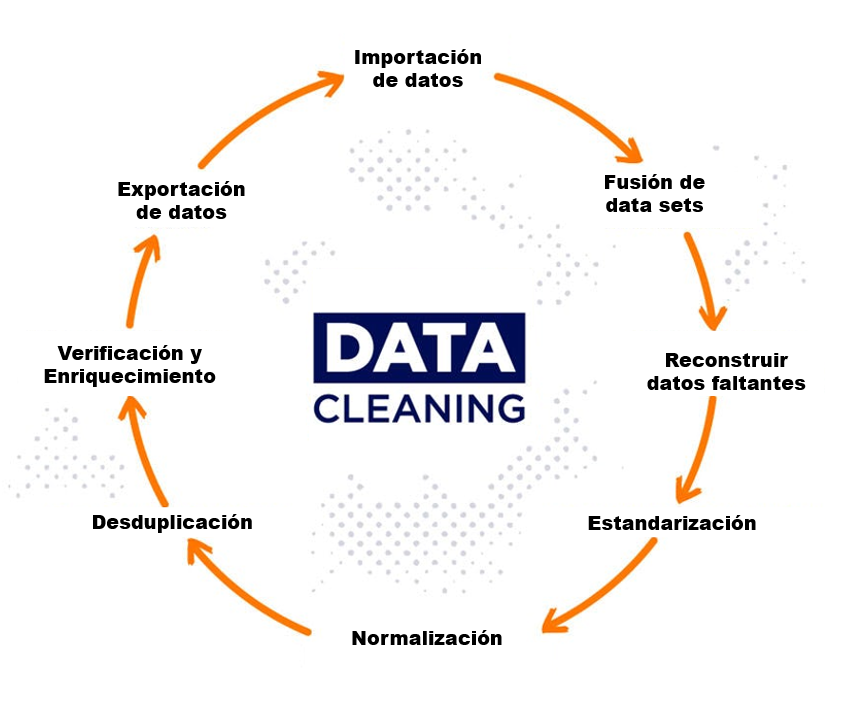
¿Cuál es el ciclo de limpieza de datos en data cleansing?
El ciclo de limpieza de datos en data cleaning consiste en los siguientes pasos:
1. Análisis de los datos: examinar los datos para identificar datos incompletos, incorrectos, inconsistentes, duplicados, etc.
2. Preprocesamiento de datos: convertir los datos a un formato adecuado para su uso, y aplicar transformaciones para ajustar y limpiar los datos.
3. Corrección de datos: identificar y corregir los datos incorrectos o inconsistentes.
4. Completado de datos: rellenar los datos faltantes con valores razonables.
5. Agregación de datos: agrupar los datos existentes para resumir y extraer información significativa.
6. Análisis de datos: analizar los datos limpios para obtener información útil y clasificar los datos para su uso posterior.
7. Presentación de los datos: presentar los datos de forma adecuada para su uso.
¿Qué técnicas se aplican en data cleansing?
1. Verificación de los datos: Esta técnica implica verificar los datos para asegurarse de que están completos y correctos; esto puede incluir comprobar el formato de los datos, así como comprobar los límites de los valores de los datos. Algunos ejemplos de verificación de datos son:
- Verificación de valores límite: Esta técnica se usa para verificar si los valores están dentro de los límites esperados. Por ejemplo, una empresa puede verificar los ingresos de algunos empleados para asegurarse de que no excedan el límite de impuestos.
- Verificación de la consistencia de los datos: Esta técnica se usa para verificar si los datos dentro de un conjunto de datos son coherentes entre sí. Por ejemplo, una empresa puede verificar si los salarios de los empleados se corresponden con los niveles de cargo asignados.
- Verificación de la integridad de los datos: Esta técnica se usa para verificar si los datos están completos y sin errores. Por ejemplo, una empresa puede verificar la integridad de los datos de una encuesta para asegurarse de que todas las preguntas se han respondido y que los datos no han sido manipulados.
- Verificación de la precisión de los datos: Esta técnica se usa para verificar si los datos son correctos y precisos. Por ejemplo, una empresa puede verificar la exactitud de los datos de una factura para asegurarse de que las cantidades y los cálculos están correctos.
2. Eliminación de valores atípicos: Esta técnica implica identificar y eliminar los valores atípicos, ya sean datos incompletos, inconsistentes o incorrectos. Algunos ejemplos de eliminación de datos son:
- Reemplazo de valores atípicos: consiste en reemplazar los valores atípicos con algún valor que sea más acorde con los datos. Por ejemplo, si una variable contiene datos en la escala 0-10, un valor atípico de 20 puede ser reemplazado por 10.
- Eliminación de observaciones: se eliminan las observaciones que contienen valores atípicos. Esta es una solución muy drástica, ya que se pierden información importante.
- Eliminación de los valores extremos: se eliminan los valores atípicos ubicados en los extremos de la distribución. Por ejemplo, en una distribución normal, los valores atípicos ubicados por encima del percentil 99 y por debajo del percentil 1 pueden ser eliminados.
- Transformación de los valores atípicos: los valores atípicos pueden ser transformados a valores más acordes con los datos. Por ejemplo, se pueden transformar los valores atípicos a la mediana de los datos.
3. Normalización de datos: Esta técnica implica aplicar una transformación a los datos para asegurarse de que se encuentran en un formato consistente y/o de que sus valores sean comparables. Algunos ejemplos de normalización de datos son:
- Eliminación de valores duplicados: Se trata de identificar los registros duplicados y eliminarlos del conjunto de datos.
- Agregar campos normalizados: Esto significa agregar un campo a los datos que contenga los valores normalizados para que sean más fáciles de comparar.
- Estandarización de los datos: Esto significa convertir los datos a un formato común para que sean más fáciles de analizar.
- Establecimiento de rangos: Esto significa establecer un rango para ciertos datos para que sean más fáciles de analizar.
- Reducción de la dimensionalidad: Esto significa eliminar los atributos innecesarios para reducir la complejidad de los datos.
4. Combinación de datos: Esta técnica implica combinar datos de diferentes fuentes para obtener un conjunto de datos más completo. Algunos ejemplos de combinación de datos son:
- Unificación de datos: combinar varias fuentes de datos en una sola para tener una mejor comprensión de los datos.
- Agregación de datos: juntar datos de diferentes fuentes para crear una sola vista consolidada.
- Fusión de datos: combinar datos de diferentes fuentes para crear una sola base de datos con información adicional.
- Normalización de datos: asegurarse de que los datos estén en el mismo formato para facilitar la comparación.
- Completar datos: añadir información a los datos existentes para mejorar la calidad del conjunto de datos.
- Verificación de datos: comprobar la exactitud de los datos comparándolos con otros conjuntos de datos.
5. Agrupamiento de datos: Esta técnica implica agrupar datos similares para facilitar su análisis. Algunos ejemplos de agrupamiento de datos son:
- Fusionar columnas de datos: combinar columnas con datos similares en una sola columna para facilitar el análisis.
- Establecer valores atípicos: identificar valores atípicos y decidir si se deben conservar, modificar o eliminar.
- Formatear los datos: asegurarse de que los datos estén en el formato correcto para su posterior análisis.
- Agrupar datos: agrupar los datos en categorías para facilitar su análisis.
- Crear grupos de datos: agrupar los datos en grupos lógicos, como números enteros, decimales, fechas, etc.
6. Detección de anomalías: Esta técnica implica identificar patrones anómalos en los conjuntos de datos que puedan indicar alguna actividad sospechosa.
- Anomalías de valores extremos: Comprobar si los valores máximos y mínimos para cada columna se encuentran dentro de un rango esperado.
- Anomalías de valores faltantes: Verificar si hay valores faltantes en un conjunto de datos.
- Anomalías de valores duplicados: Buscar registros duplicados en un conjunto de datos.
- Anomalías de valores no numéricos: Verificar si hay valores no numéricos en las columnas numéricas.
- Anomalías de valores atípicos: Detectar valores atípicos como outliers utilizando herramientas de análisis estadístico como histogramas y boxplots.
¿Qué herramientas se utilizan en data cleansing?
Las herramientas comunes para el proceso de limpieza de datos incluyen:
- Excel: Excel es una herramienta común para la limpieza de datos ya que ofrece una variedad de funciones para manipular datos y detectar errores.
- Power Query: Power Query es una herramienta de Microsoft para la limpieza y preparación de datos. Ayuda a los usuarios a recopilar y combinar datos desde diferentes orígenes, descubrir patrones y relaciones en los datos y generar informes.
- Tableau Prep: Tableau Prep es una herramienta de limpieza de datos diseñada para limpiar, combinar y preparar datos para su análisis.
- OpenRefine: OpenRefine es una herramienta de limpieza de datos gratuita, de código abierto, que ayuda a los usuarios a limpiar, reorganizar y transformar datos sin escribir líneas de código.
- Talend: Talend es una herramienta de limpieza de datos de código abierto que ayuda a los usuarios a limpiar, transformar y preparar datos para su análisis.
- Google Refine: Google Refine es otra herramienta para la limpieza y preparación de datos que ayuda a los usuarios a limpiar, reorganizar y transformar datos sin escribir código.
- Trifacta: Trifacta es una herramienta para la limpieza y preparación de datos diseñada para ayudar a los usuarios a limpiar, transformar y reconciliar datos rápidamente.
¿Cómo se utiliza la inteligencia artificial en data cleansing?
La inteligencia artificial (IA) se puede utilizar en data cleaning para hacer tareas como la identificación de patrones, la corrección de errores y la eliminación de datos duplicados. Con la ayuda de algoritmos especializados, la IA puede identificar y corregir errores de datos, como valores aberrantes, datos incompletos, entradas incorrectas, entradas duplicadas, etc. La IA también puede ayudar a detectar y eliminar datos duplicados. Además, con la ayuda de la IA, los usuarios pueden adecuar los datos a un formato específico y rellenar los valores vacíos con datos confiables.
Fuentes
Algunas ventajas que ofrece la depuración de datos o data cleansing <https://blog.powerdata.es/el-valor-de-la-gestion-de-datos/algunas-ventajas-que-proporciona-la-depuracion-de-datos>
8 Ways to Clean Data Using Data Cleaning Techniques <https://www.digitalvidya.com/blog/data-cleaning-techniques/>
La importancia del preprocesamiento de datos en Inteligencia Artificial: Limpieza de datos <https://www.xeridia.com/blog/la-importancia-del-preprocesamiento-de-datos-en-inteligencia-artificial-limpieza-de-datos>